
On August 1st, Kyligence presented an Apache Kylin tech talk at a Meetup hosted by Big Data Bellevue.
For those unfamiliar, Big Data Bellevue is an active Meetup group in Seattle’s Eastside area, run by Siddharth Agrawal and Chaitanya Dabke. Its members are technology professionals from Seattle, Bellevue, Redmond, Kirkland, and other neighboring cities. Over the past five years, it has produced many excellent sessions focused on Big Data technologies. We were very excited to have a chance to present at this Meetup.
Architects and engineers from eBay, T-Mobile, Amazon, Microsoft, and other major organizations attended the talk. Daniel Gu, VP of the Americas at Kyligence, and Shaofeng Shi, Kyligence’s Chief Architect, delivered the presentation. The discussion started with Daniel, an eBay veteran who oversaw the company’s global analytics platform. He recounted the story of how the business’ need to analyze millions of transactions interactively gave birth to a new analytics project. That project would eventually go on to become Apache Kylin.
Daniel shared his view of the evolution of data processing over the past two decades and busted the myth that OLAP is dead. A great overview of this can be found in his blog article on the subject: OLAP Analytics is Dead. Really?.
Shaofeng Shi is one of the original creators of the Apache Kylin project, an Apache Kylin PMC member, and one of Kyligence’s founding engineers. He has been an evangelist for Apache Kylin over the past few years, giving speeches at various open source conferences around the world. At Kyligence, Shaofeng helps the company’s largest customers setup analytics architectures that processes trillions of rows of data while servicing 100,000+ active users.
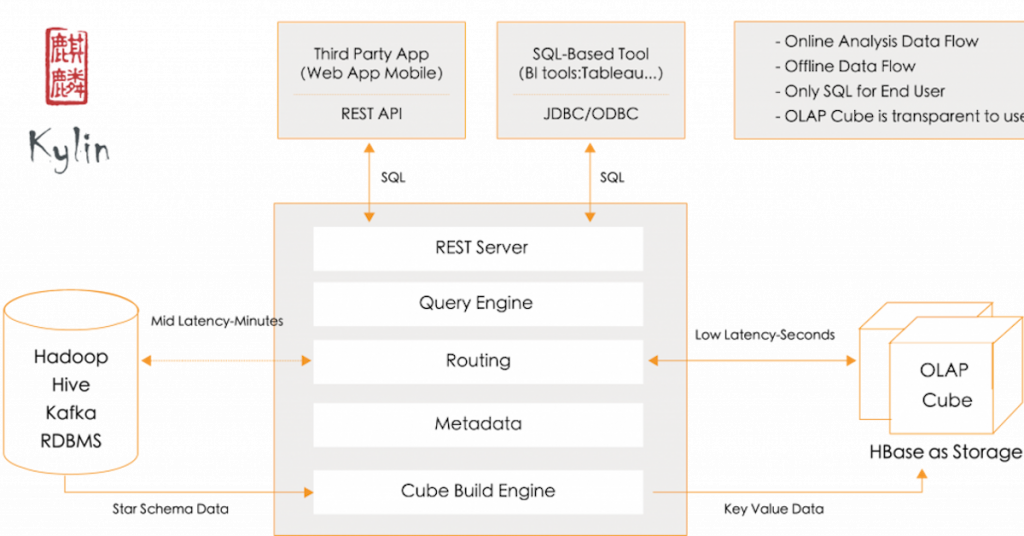
Shaofeng’s portion of the talk introduced the latest addition to Apache Kylin 3.0, Real-Time Analytics, which is scheduled for GA later this year.
Traditionally, the Kylin OLAP engine was designed to process historical data stored in data lakes in a format such as Hive tables. Near real-time processing was added in Kylin 1.5. Near real-time processing reads data from stream data sources like Kafka and updates the cube in a mini-batch fashion. Previously, the delay of Kylin’s near real-time processing was at around one minute. This is not enough for certain use cases such as fraud alert in financial transactions.
In Kylin 3.0, aggregation data (cubes) are stored in real-time servers and/or historical servers (see diagram below). The data query request is divided into two parts according to the Timestamp Partition Column. The query request of the latest time period will be sent to the real-time node, and the query request for historical data will still be sent to the HBase region server.
The query server needs to merge the results of both and return it to the client. At the same time, the real-time node will continuously upload the local data to the HDFS. When a certain condition is met, the segment will be built by MapReduce, thereby realizing the conversion of the real-time part to the historical part and achieving the purpose of reducing the pressure on the real-time computing node.
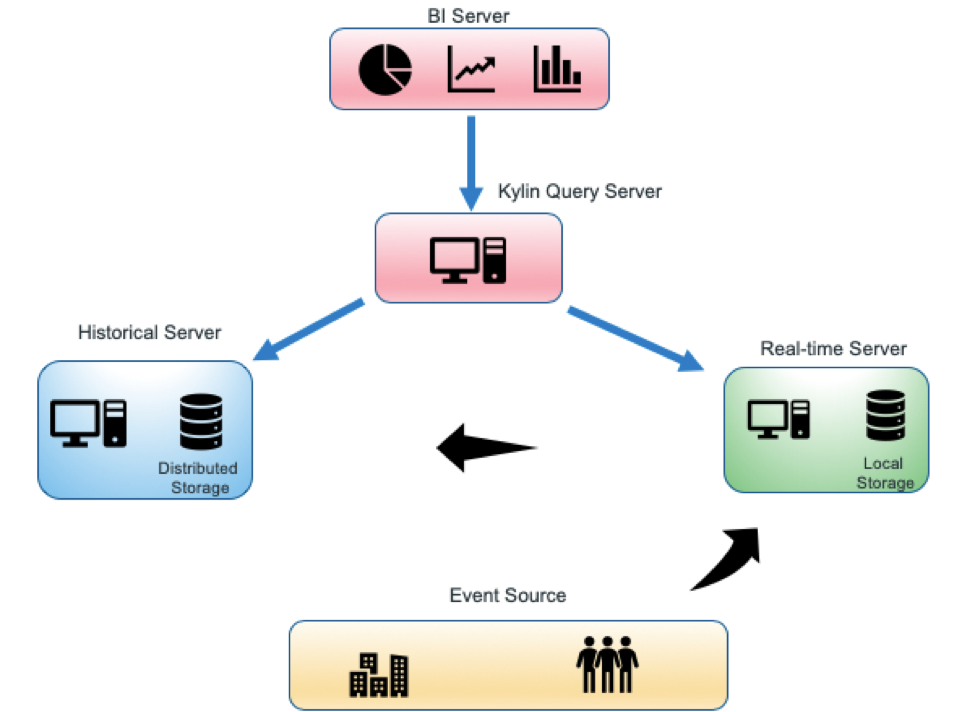
With real-time processing capabilities, Kylin can now serve multidimensional analysis for both historical and real-time data. This opens doors for many use cases in financial services, IOT, healthcare, retail, ad tech, and more major industries.
Customers can now process all of their analytical queries with one technology – Kylin. This greatly simplifies the technology architecture and improves productivity and accuracy of analysis. For more details about Kylin real-time analysis, please visit this page.
The Big Data Bellevue Meetup was a wonderful opportunity and we appreciate having had the chance to share Kylin’s story and connect with so many great members of the Washington Big Data community. We look forward to attending again in the future. If you’d like for us to speak at your next Meetup or community event, feel free to contact us.
Also be sure to follow us on Twitter and LinkedIn for the latest updates regarding Apache Kylin, Kyligence Enterprise, Kyligence Cloud, and Kyligence Insight.


