

When we look back at 2021, the pandemic did not stop the development and progress of technology. Buzzwords such as Metrics Store and Data Mesh have emerged in the big data industry and some other jargon is fading out. We have referred to many research and consulting companies such as Gartner, Thoughtworks, and Forrester Research to examine the Top 7 data buzzwords to prepare you for the year of 2022 and interpret the technologies behind them.
Content
- Metrics Store/Headless BI
- Data Lakehouse
- Intelligent Data Cloud
- Data Catalog
- Data Fabric
- Data Mesh
- Data as a Product
You may have already noticed that, the first four buzzwords are more concrete, while the last three buzzwords are more abstract like design concepts.
Now let’s start the buzzwords tour.
1. Metrics Store / Headless BI
Metrics Store is, in the simplest words, a middle layer between upstream data warehouses/data sources and downstream business applications. It can be called the Metric Platform, Headless BI, the Metric Layer, or the Metrics Store — — they are ultimately the same thing.
As described by Ankur in his article Headless Business Intelligence and the Airbnb data team in their article How Airbnb Achieved Metric Consistency at Scale, with Headless BI/Metrics Store, the teams that own metrics could define them once, consume them everywhere, in a way that’s consistent across dashboards, automation tools, sales reporting, and so on.
The core question — Why do we need an extra Metric Layer?
In the past, metrics were usually defined in data warehouses or BI applications, but this is causing increasing pains for enterprises with growing data volume and complexity. The rise of Metrics Store is essentially an attempt to find solutions for these challenges enterprises are encountering:
- Inconsistency of key metrics definition between business causing discrepancy for decision-making
- Incapability to reuse defined metrics in different business applications and BI dashboards
- The difficulty for business users to define metrics with SQL
- The high complexity of data architecture and pipelines results in low efficiency of data analytics
Here are the Growing Pains that the Airbnb data team Robert Chang has experienced:
“New tables were created manually every other day, but there was no way to tell if similar tables already existed. The complexity of our warehouse continued to grow, and data lineage became impossible to track. When a data issue upstream was discovered and fixed, there was no guarantee that the fix would propagate to all downstream jobs. As a result, data scientists and engineers spent countless hours debugging data discrepancies, fighting fires, and often feeling unproductive and defeated.”
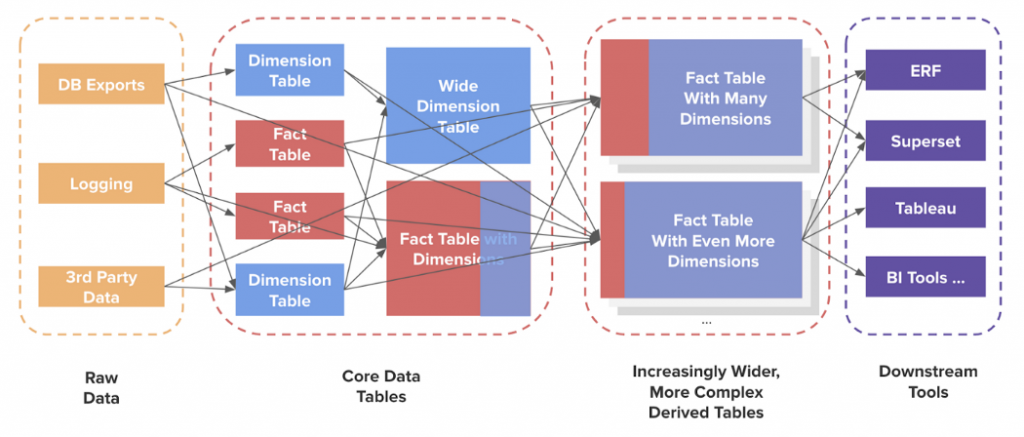
It’s easy to understand why Airbnb invested significantly to design Minerva, Airbnb’s metric platform that is used across the company as the single source of truth for analytics, reporting, and experimentation.
From a technical perspective, Metrics Store can cover the full life cycle from metric creation through computation, serving, consumption, and deprecation just like Minerva at Airbnb does.
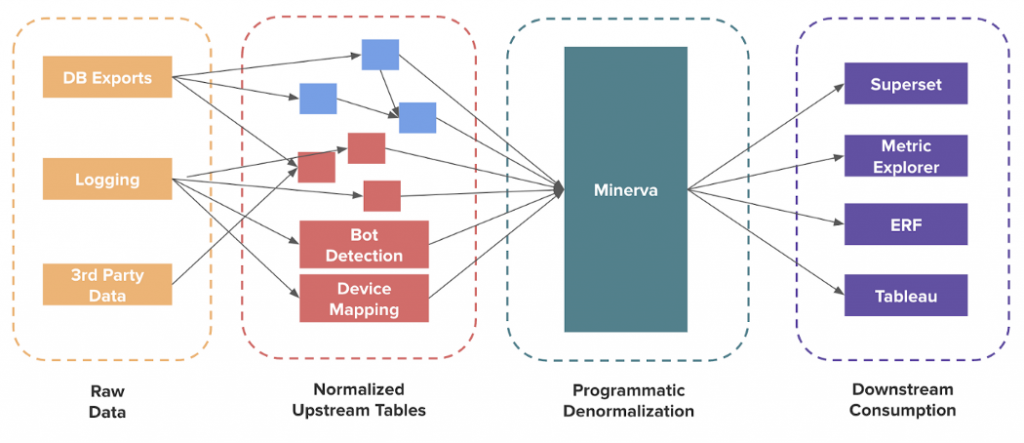
As Metrics Store is a rather new concept in the market, there are not many companies providing Metrics Store solutions, but we already see a trend in this field driven by the demand from enterprises.

If you are interested in more Metrics Store best practices, I’d highly recommend that you read Enterprise Metric Platform in Actionby Lori Lu and the articles that I listed in the reference list.
2. Data Lakehouse
Data Lakehouse is a new, open architecture proposed by Databricks. A data lakehouse is a data management architecture that combines the flexibility, cost-efficiency, and scale of data lakes with the data management and ACID transactions of data warehouses, enabling business intelligence (BI) and machine learning (ML) on all data.
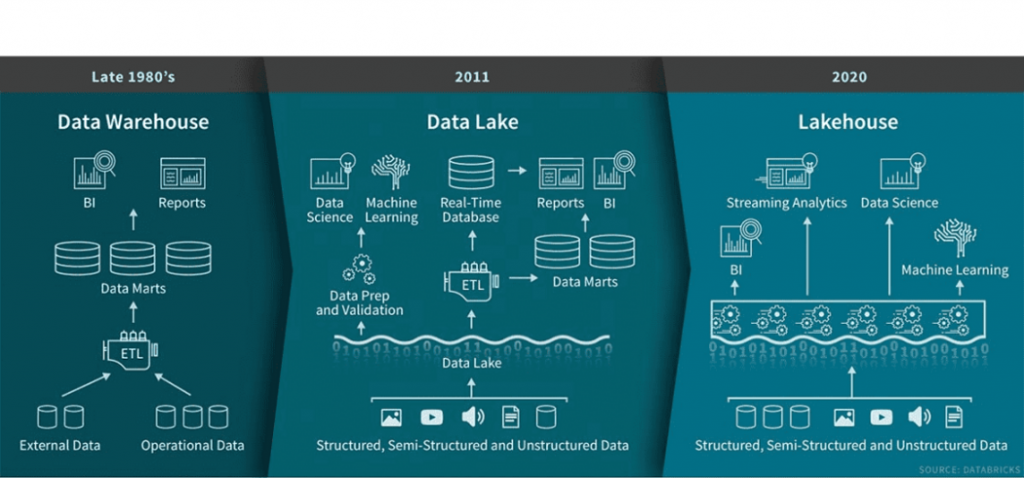
According to Bill Inmon, who has long been considered the father of data warehouses, the data lakehouse presents an opportunity similar to the early years of the data warehouse market. The data lakehouse can “combine the data science focus of the data lake with the analytics power of the data warehouse.”
Data Lake vs. Data Warehouse vs. Data Lakehouse
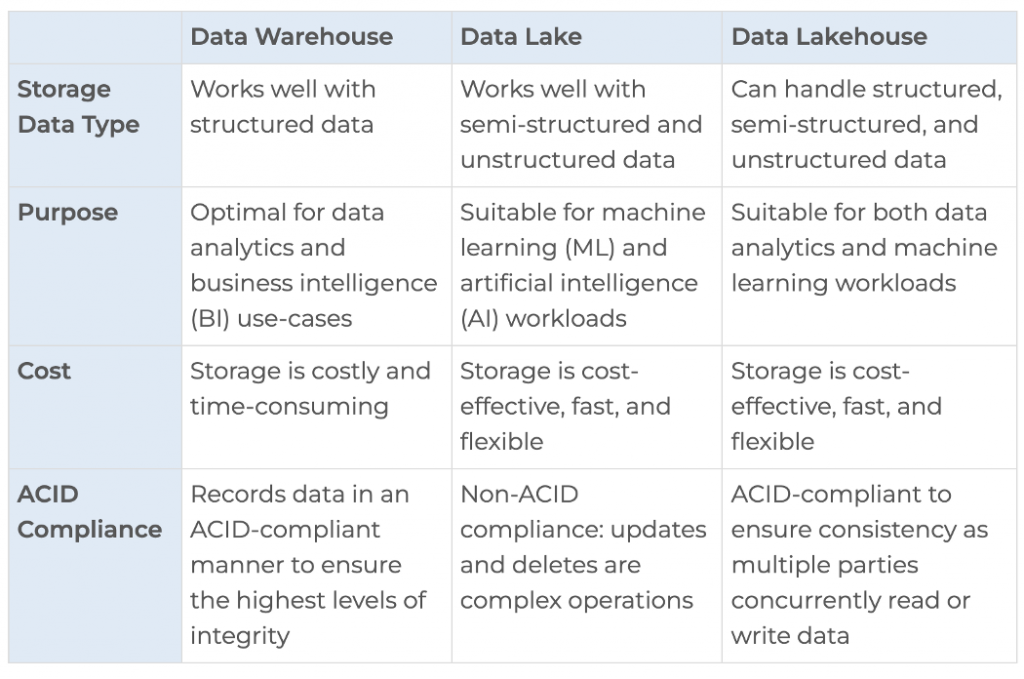
The comparison between the data lakehouse, the data warehouse, and the data lake is still an ongoing debate. The choice of data architecture should ultimately depend on the type of data you’re dealing with, the data source, and how the stakeholders will use the data.
In terms of products/solutions of data lakehouse, the most typical one is the Delta Lake provided by Databricks, but some other products with the same value proposition are also emerging such as Iceberg open-sourced from Netflix, and Hudi open-sourced from Uber.
3. Intelligent Data Cloud
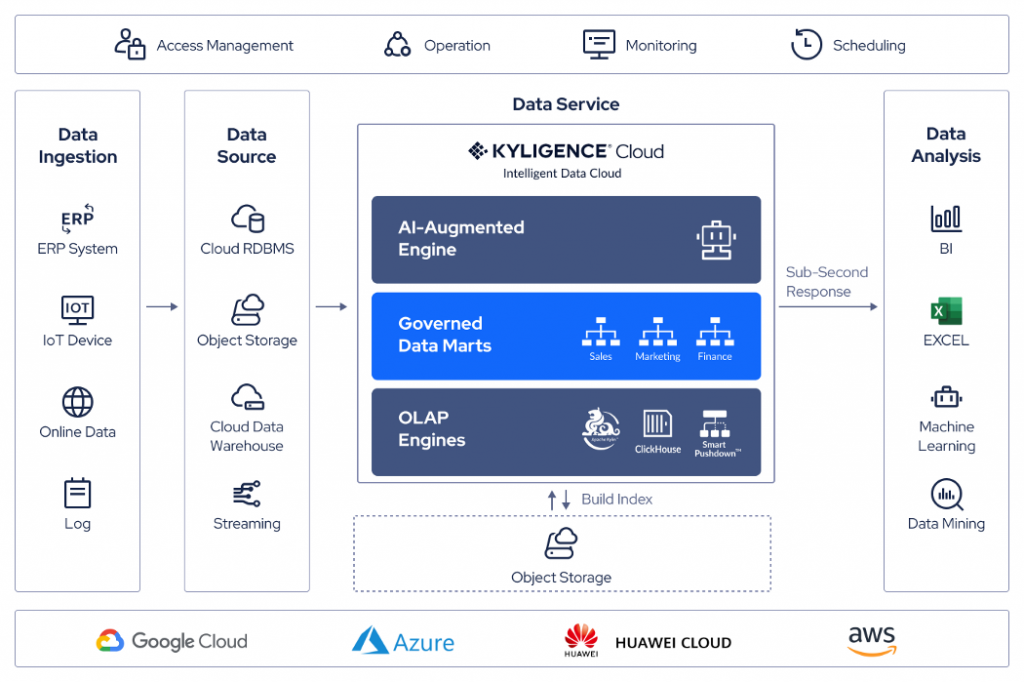
Intelligent Data Cloud is defined as the next-generation cloud-native big data services and management platform by Kyligence. An intelligent data cloud can identify the most valuable data automatically, deliver optimal performance at a petabyte-scale of data and concurrency, and be governed by a unified semantic layer to provide access to BI tools.
Is the Intelligent Data Cloud another type of the data lake?
Kyligence does claim that the Intelligent Data Cloud is an OLAP(online analytical processing) on Data Lake solution.
From the technical perspective, the intelligent data cloud carries the core competencies and is a continuation of the previous technical systems such as the data warehouse, data lake, and data lakehouse. It has both the cost-efficiency and scalability of the data lake and the robust data structure and data management ability of the data warehouse. Below are some main features of the intelligent data cloud defined by Kyligence:
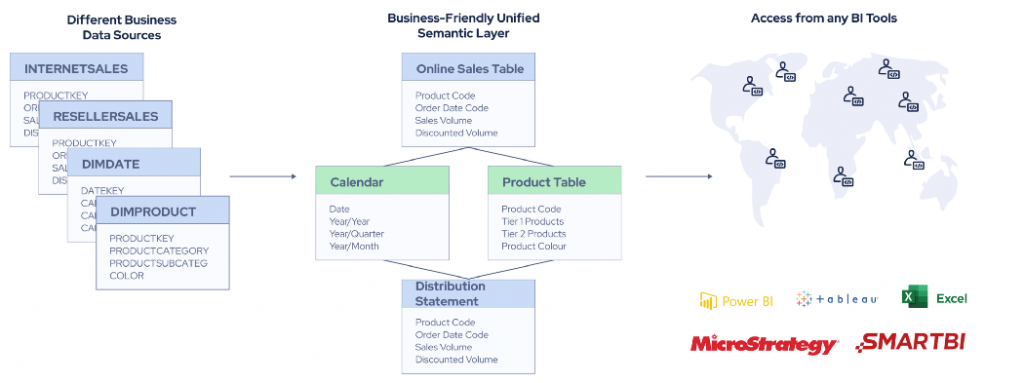
- Unified semantic layer — to define standardized metrics and eliminate data silos
- AI-Augmented and automated — to remove the high barrier to conventional modeling
- Cloud-native architecture — to achieve high availability, multi-tenant isolation, high throughput, load balancing, and low monitoring and O&M workloads
- Unified data services — to support data acquisition from different platforms including streaming data, databases, data lakes, and clouds, while providing a unified interface for downstream applications
In terms of a typical data analytics pipeline, the intelligent data cloud sits between data sources — RDBMS, data warehouses, data lakes — and the data analysis layer where BI tools, machine learning systems, and SaaS dashboards live.
A unified semantic layer of intelligent data cloud is a business abstraction derived from the technical implementation layer to uniformly maintain business logic. It is on top of the intelligent data cloud to map complex data into clear business terms. The dimensions, measures, and hierarchies familiar to business personnel are synchronized with mainstream BI tools through a unified semantic layer to create a unified and reusable set of business semantics.
The AI-Augmented and automated part of the intelligent data cloud comes from an AI-augmented engine to automate some of the technical data engineering and management work that used to be done manually.
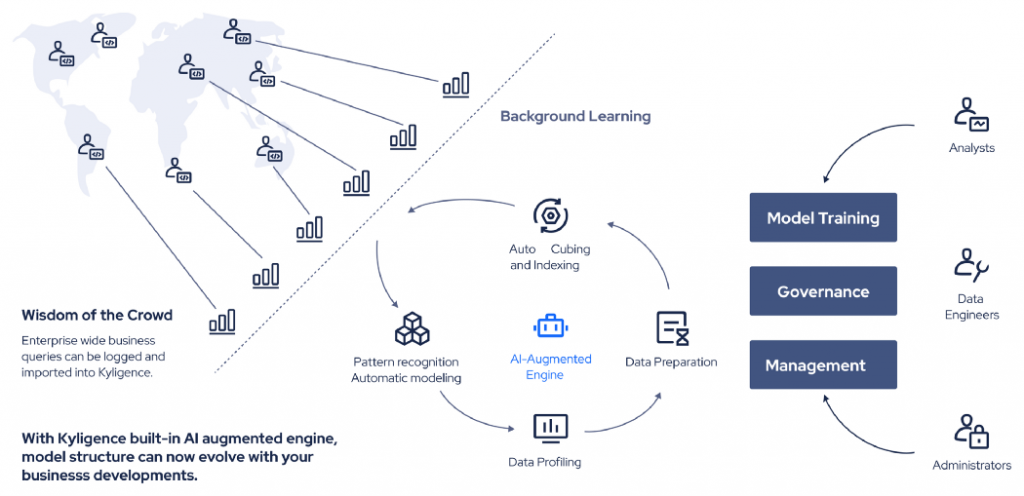
In short, externally, the intelligent data cloud provides data services and data products available to citizen data analysts and business users; internally, the intelligence data cloud automates data management, governance, and modeling with a business-driven “mindset”.
4. Data Catalog
A data catalog is an organized inventory of data assets in an organization. Data exists in a company’s various source systems in tables, files, reports, etc. A data catalog shows the location of all data entities and much critical information about each data fragment. It helps enterprises or institutions understand the definition, source, features, users, and usage scenarios of data.
The working principle of the data catalog is like the fashion catalog. While instead of detailing swimwear or shoes, it draws information from a company’s ERP, HR, finance, e-commerce systems, and social media feeds. Data catalogs contain the most critical information about each data segment/data set. At the bare minimum, a data catalog should answer:
- Where should I look for my data?
- Does this data matter?
- What does this data represent?
- Is this data relevant and important?
- How can I use this data?
Data Catalog is the entry point of data analytics, starting from where data analysts, data admins, and data scientists find and understand data sets to build insights and spot trends. It is a critical basis for metadata management.
While a data catalog can document and manage data, the fundamental challenge of allowing users to “discover” and glean meaningful, real-time insights about the health of your data has largely remained unsolved. This is why Debashis Saha, VP of Engineering at a Leading Finance AI Platform, has claimed that “data catalogs aren’t meeting the needs of the modern data stack,” and a new approach — data discovery — is needed to facilitate metadata management and data reliability better.
5. Data Fabric
Data Fabric is an emerging design concept that serves as an integrated layer (fabric) of data and connecting processes.
Data Fabric can be a “robust solution to ever-present data management challenges, such as the high-cost and low-value data integration cycles, frequent maintenance of earlier integrations, the rising demand for real-time and event-driven data sharing and more,” says Mark Beyer, Distinguished VP Analyst at Gartner.
In 2018, ‘Data Fabric’ first appeared in Gartner’s top 10 data analytics technology trends and remained in Gartner’s reports in recent years. A data fabric utilizes continuous analytics over metadata assets to support the design, deployment, and utilization of integrated and reusable data across all environments, including hybrid and multi-cloud platforms.
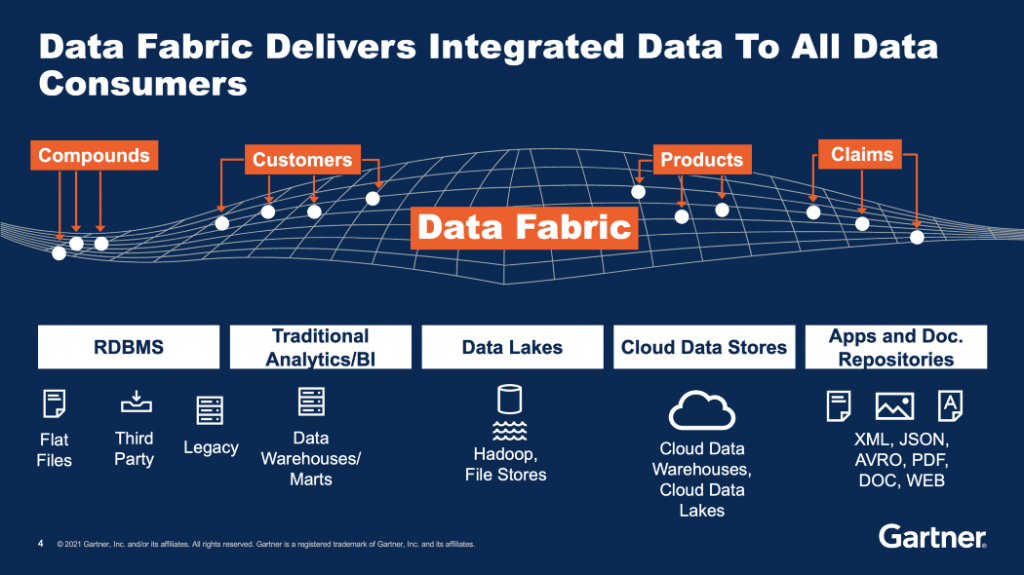
Data fabric combines key data management technologies — such as data catalogs, data governance, data integration, data pipelining, and data orchestration. A well-designed data fabric architecture is modular and supports massive scale, distributed multi-cloud, on-premise, and hybrid deployment.
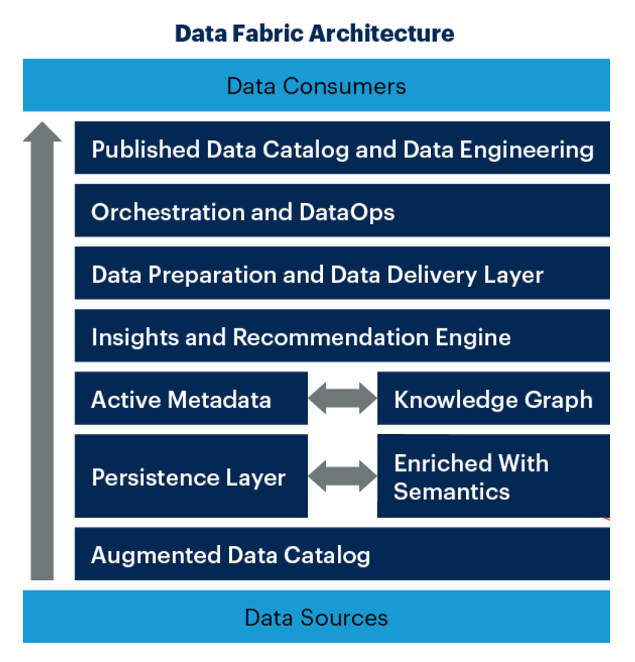
In the data fabric architecture, as data is provisioned from sources to consumers, it is cataloged, enriched to provide insights and recommendations, prepared, delivered, orchestrated, and engineered. Data sources range from siloed legacy systems to the most modern cloud environments; Data consumers include data scientists and data analysts, marketing, sales, data privacy specialists, cloud architects, and more.
As data fabric becomes a trending topic, many internationally renowned IT companies such as IBM, Informatica, Talend etc. have introduced data fabric solutions.
6. Data Mesh
The design concept of data mesh was introduced by Zhamak Dehghani at Thoughtworks. It is a decentralized sociotechnical approach to remove the dichotomy of analytical data and business operation. Its objective is to embed sharing and using analytical data into each operational business domain and close the gap between the operational and analytical planes.
Current data platforms often have the following underlying characteristics: centralized, monolithic, with highly coupled pipeline architecture, operated by silos of hyper-specialized data engineers. The data mesh platform proposed by Dehghani was created to solve these problems.
This new data architecture is founded on four principles:
- Domain-oriented decentralized data ownership
- Data as a product
- Self-serve data platform
- Federated Computational federated governance
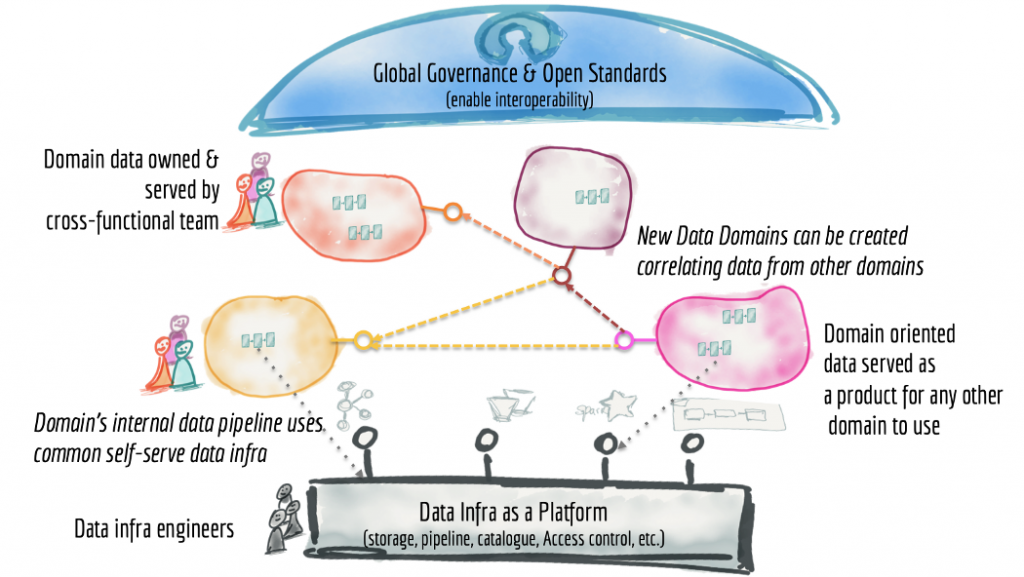
The building blocks of a ubiquitous data mesh as a platform are as follows: distributed data products oriented around domains and owned by independent cross-functional teams who have embedded data engineers and data product owners, using common data infrastructure as a platform to host, prep, and serve their data assets.
You might ask what’s the organizational impact of this architecture?
With the data domain being the core component of data mesh, enterprises are split into mini enterprises, each taking responsibility for building abstractions, serving data, maintaining associated metadata, improving data quality, applying life cycle management, performing code control and so on.
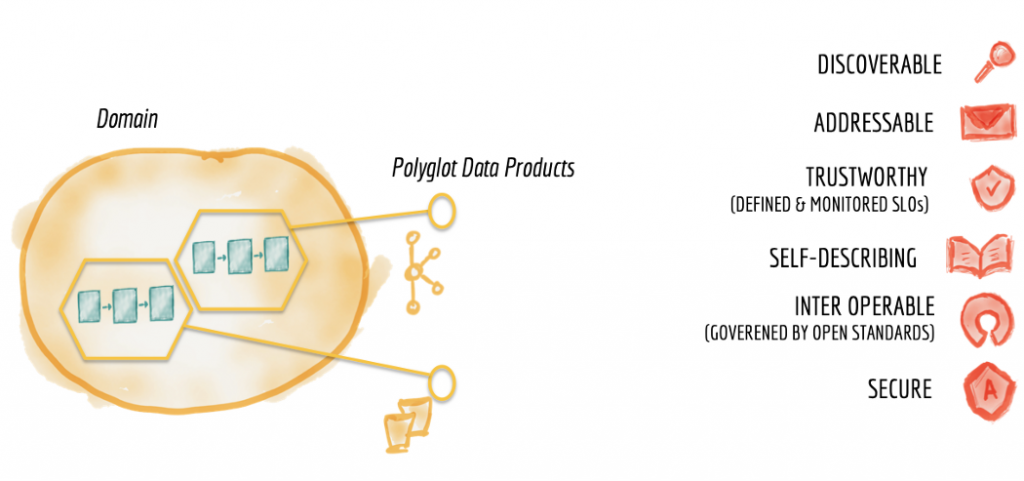
And where does the data lake or data warehouse fit in the data mesh? They are simply nodes on the mesh. Data lakes and data warehouses may no longer be needed because the distributed logs and storage that hold the original data are available for exploration from different addressable immutable datasets as products. However, in cases where we do need to make changes to the original format of the data for further exploration, such as labeling, the domain with such need might create its own lake or data hub.
7. Data as a Product
US Chief Data Scientist DJ Patil defined the data product as “a product that facilitates an end goal through the use of data.”
In the era of big data, we need to change the way we think about data, and data should become a product: it has ‘customers,’ and its objective is to keep these ‘customers’ — data analysts and data scientists — happy. It can be said that every company is a data company. And these valuable data assets can be packaged as products to become data products.
Such data products are no stranger to the public. For ordinary consumers, they can always see these data products in daily life. It can be an electronic bill in our mobile banking, or it can be a Covid-19 cases tracker like this one.
Summary
Whether you are a newbie to the data industry or have years of experience in this field, it’s imperative that you keep yourself up-to-date on these data buzzwords and the tech deep dive behind them.
To summarize, the 7 must-know data buzzwords are:
- Metrics Store/Headless BI
- Data Lakehouse
- Intelligent Data Cloud
- Data Catalog
- Data Fabric
- Data Mesh
- Data as a Product
If you have opinions about this topic or are looking for a solution around Metrics Store, we would love to hear from you!
References:
- Using Data Fabric Architecture to Modernize Data Integration
- What is data fabric? Modern Enterprise Data Architecture
- Six steps to building a data catalog
- Every product will be a data product
- Evolution to the Data Lakehouse
- Whitepaper: The Data Mesh Shift
- What is data fabric? Modern Enterprise Data Architecture
- Building the Data Lakehouse
- Data Warehouse vs. Data Lake vs. Data Lakehouse: An Overview of Three Cloud Data Storage Patterns |
- Data Domains — Where do I start?
- Data Catalogs Are Dead; Long Live Data Discovery
- How Airbnb achieved metric consistency at scale
- The missing piece of the modern data stack


